
Docker学习
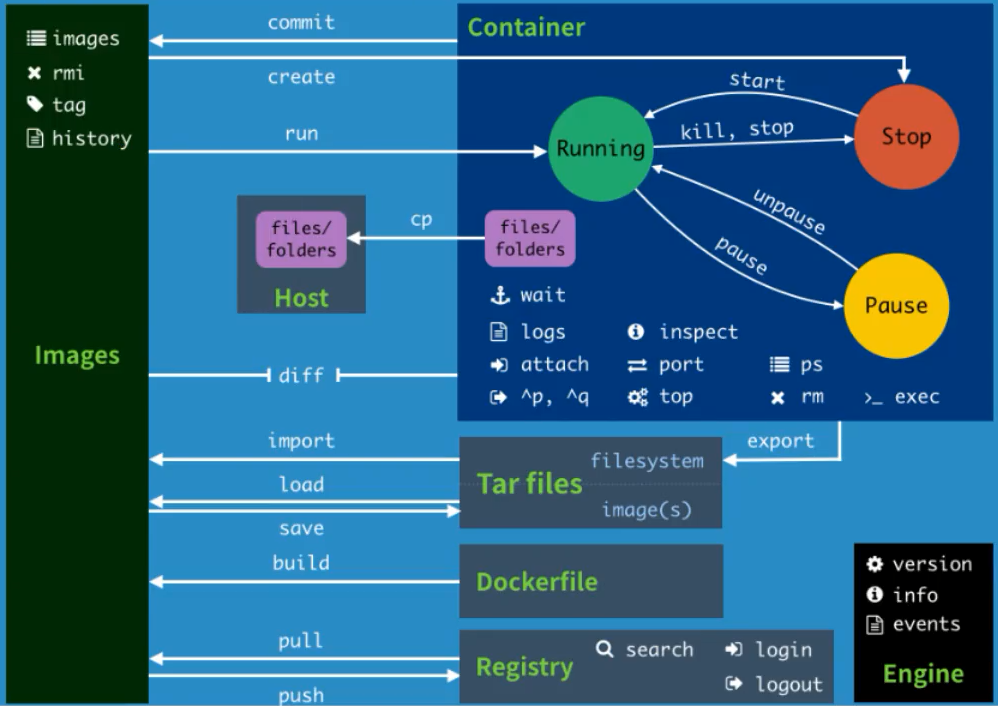
运行容器
docker run -d -p 80:80 docker/getting-started
docker run -dp 80:80 docker/getting-started-d - 以分离模式(在后台)运行容器
-p 80:80 - 将主机的80端口映射到容器的80端口
docker/getting-started - 运行的镜像名称
部署项目
下载项目
下载一个demo:https://github.com/docker/getting-started/tree/master/app
Dockerfile
将 app 复制到 linux 里
在文件 package.json 所在的文件夹中创建一个名为 Dockerfile 的文件
创建镜像
打开一个终端,并进入 Dockerfile 所在的目录。使用 docker build 命令构建容器映像。
-t - 标记镜像,可以看成是镜像最终的名称。由于我们将这个映像命名为 getting-started,因此在运行容器时可以引用这个映像。
. - 在 Docker build 命令的末尾告诉 Docker 应该在当前工作目录文件中寻找 Dockerfile
启动
在浏览器中访问:http://[host ip]:3000
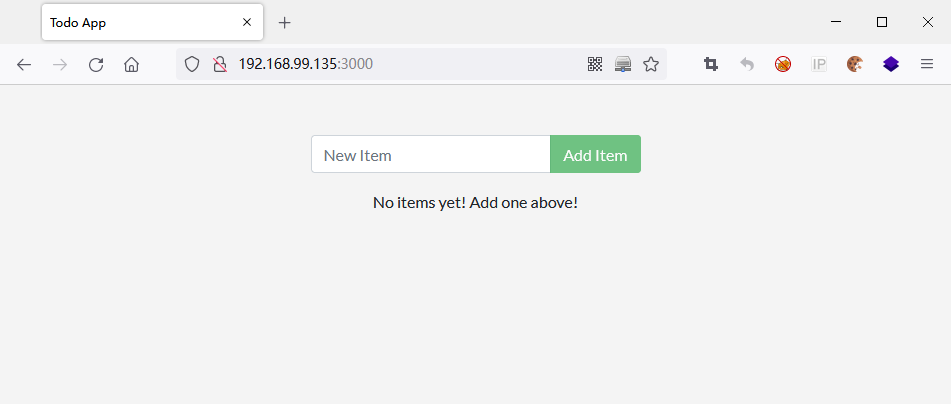
更新应用程序
我们希望将 web 页面中的字符串改成 You have no todo items yet! Add one above!
对 src/static/js/app.js 文件中的第56行进行修改
使用之前的命令更新版本并启动
此时我们需要移除旧的容器才能成功启动
现在,开始更新你的应用程序
在浏览器中访问:http://[host ip]:3000
共享 Docker 镜像
注册或登录到 Docker Hub,单击 Create Repository 按钮,对于仓库的名称,使用 getting-started。确保 Visibility 为 Public。点击创建按钮!
完成之后你可以看到一个示例 Docker 命令。这个命令将推送这个仓库。

此时我们需要为我们已经构建的现有图像“添加标签”,以便给它另一个名称
使用命令登录到 Docker Hub
使用 docker 标记命令为刚开始使用的图像命名
现在再试一次 push 命令。如果要从 dockerhub 复制值,可以删除 tagname 部分,因为我们没有向图像名称添加标记。如果不指定标记,Docker 将使用名为 latest 的标记。
在新实例上运行镜像
打开浏览器登录:https://labs.play-with-docker.com/
登录后,单击左侧栏上的 ADD NEW INSTANCE 选项
在终端中,启动刚刚推出的应用程序
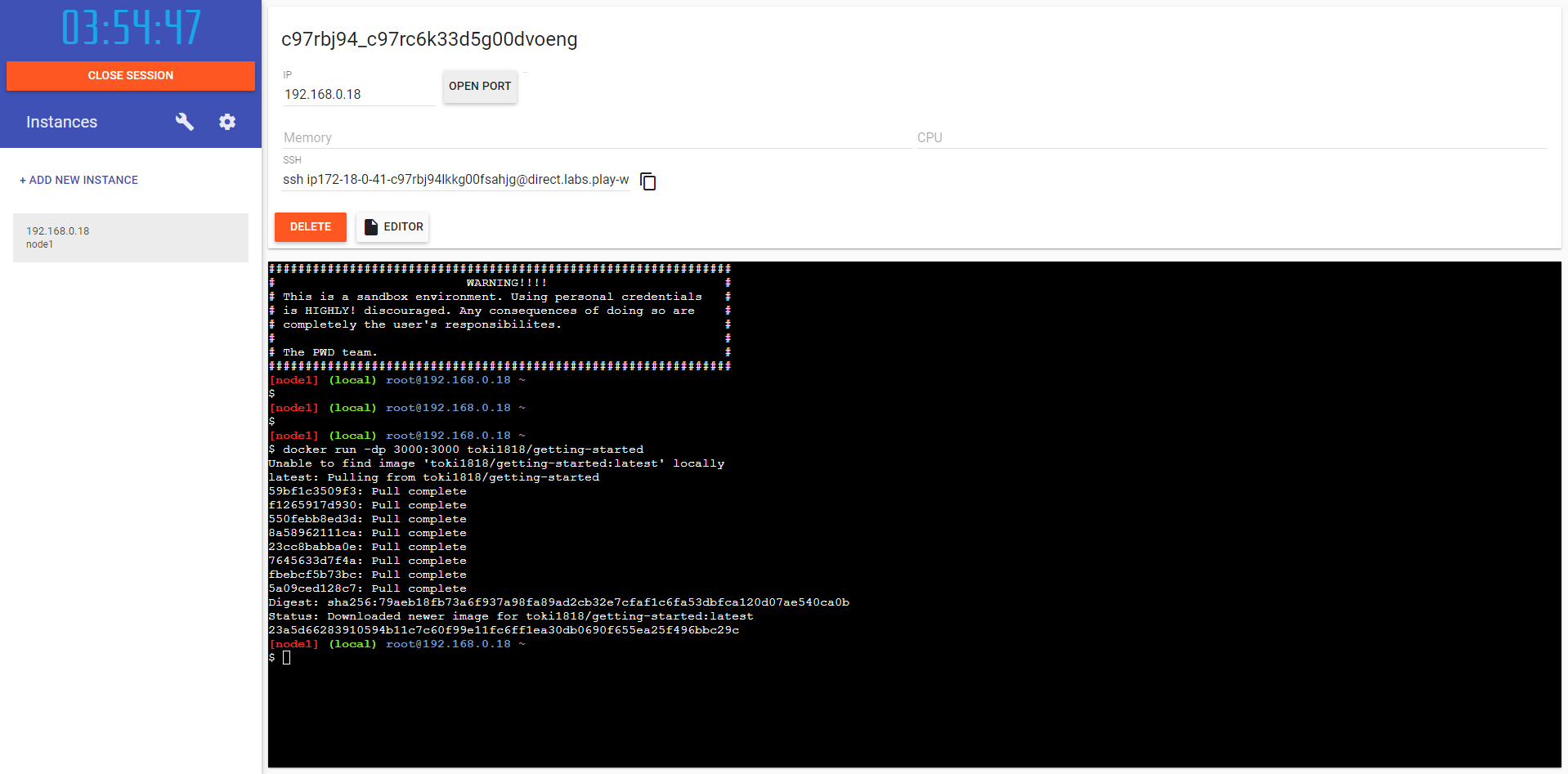
此时,点击 Open Port 按钮,并输入 3000 端口号
命名卷
如何在重新启动时持久化数据?
卷提供了将容器的特定文件系统路径连接回主机的能力。如果挂载了容器中的目录,那么在主机上也可以看到该目录中的更改。如果我们在容器重新启动时挂载相同的目录,我们会看到相同的文件。
由于数据库是一个单独的文件,我们可以将该文件持久化到主机上,并使其可用于下一个容器。
通过创建一个卷并将其附加到存储数据的目录(通常称为“挂载”)。
创建一个名为 todo-db 的命名卷
停止并删除 todo app 容器
启动 todo 应用程序容器时添加-v 标志来指定卷挂载。
我们将使用指定的卷并将其挂载到/etc/todos,它将捕获在路径中创建的所有文件。
在这个启动的容器开启后,往 todo 里添加数据。当删除这个容器再创建一个新的容器时,之前添加的数据就被持久化下来了。
可以查看卷的详细内容:
其中的 Mountpoint 就是数据存储在磁盘上的实际位置,默认存储在 /var/lib/docker/volumes/todo-db/_data
如果我们只是想存储数据,命名卷是很好的,因为我们不必担心数据存储在哪里。
绑定挂载
使用绑定挂载,我们可以控制主机上的精确挂载点。我们可以使用它来持久化数据,但是它通常用于向容器中提供额外的数据。
在处理应用程序时,我们可以使用绑定挂载将源代码挂载到容器中,让容器查看代码更改、响应,并让我们立即查看更改。
绑定挂载 和 命名卷 是 Docker 引擎附带的两种主要卷类型。
Host Location
Docker chooses
You control
Mount Example (using -v)
my-volume:/usr/local/data
/path/to/data:/usr/local/data
用容器内容填充新卷
Yes
No
Supports Volume Drivers
Yes
No
确保您以前没有运行任何启动容器。在 app 目录中运行下面的命令
-dp 3000:3000 - 在分离(背景)模式下运行并创建一个端口映射
-w /app - 设定「工作目录」或指令运行的工作目录
-v "$(pwd):/app" - 将当前工作目录挂载到容器里面的/app目录
node:12-alpine - 要使用的镜像及版本
sh -c "yarn install && yarn run dev" - 用 sh -c 开启一个 shell 执行字符串中的内容
可以通过日志来查看内部的执行信息,查看完日志后,按 Ctrl+C 退出
现在我们修改 src/static/js/app.js 中的第109行的内容
只需刷新页面(或打开页面),你就会立即看到浏览器中按钮的变化。
当你完成后,就可以停止容器,用下面的方法创建你的新镜像
对于本地开发设置,使用绑定挂载是非常常见的。优点是开发机器不需要安装所有的构建工具和环境。使用一个 docker 运行命令,就可以拉动开发环境并准备运行。
多容器应用
当需要在应用中增加MySQL时,为了满足一个容器只做一件事的原则,我们需要将数据库容器和应用容器进行联网。
在网络上放置容器有两种方法: 1)在开始时分配它; 2)连接现有的容器。
现在,我们将首先创建网络并在启动时附加 MySQL 容器。
创建网络
启动一个 MySQL 容器并将其附加到网络上。我们还将定义一些环境变量,数据库将使用这些环境变量来初始化数据库
要确认数据库已经建立并运行,请连接到数据库并验证其连接。
连接到 MySQL
我们将使用 nicolaka/netshoot 容器用来找到容器(每个容器都有自己的 IP 地址)
使用 nicolaka/netshoot 镜像启动一个新容器,确保它连接到同一个网络。
在容器内部,我们将使用 dig 命令,这是一个有用的 DNS 工具。我们将查找主机名 mysql 的 IP 地址。
在 ANSWER SECTION 中,您将看到 mysql 的 a 记录解析到 172.23.0.2 (您的 IP 地址很可能具有不同的值)。
虽然 mysql 通常不是一个有效的主机名,但 Docker 可以将其解析为具有该网络别名的容器的 IP 地址(还记得我们前面使用的 --network-alias 标志吗?)。这意味着我们的应用程序只需要连接到一个名为 mysql 的主机,它就会与数据库通信!
用 MySQL 运行你的应用程序
这个 todo app 支持设置一些环境变量来指定 MySQL 连接设置,它们是:
MYSQL_HOST- 运行的 MySQL 服务器的主机名MYSQL_USER- 用于连接的用户名MYSQL_PASSWORD- 连接所需的密码MYSQL_DB- 连接成功后使用的数据库
MySQL 8.0及以上版本,请确保提前运行了以下命令
我们将指定上面的每个环境变量,并将容器连接到我们的应用程序网络
此时查看容器的日志,可以看到它正在使用 mysql 数据库
现在,打开浏览器在应用程序中添加内容
连接容器中的 todos 数据库
查看数据表中的数据
Docker Compose
创建 compose 文件
在 app 项目的根目录下,创建一个名为 docker-compose.yml 的文件。
在 compose 文件中,我们将从定义模式版本开始。在大多数情况下,最好使用最新支持的版本。
接下来,我们将定义要作为应用程序的一部分运行的服务(或容器)列表。
现在,我们开始每次将一个服务转移到 compose 文件中。
定义应用程序服务
首先,定义容器的入口和容器的镜像。
我们可以为服务取任何名称(app)。该名称将自动成为网络别名,这在定义 MySQL 服务时非常有用。
通常,你会看到 image 下面有个 command,尽管不要求排序。
让我们通过
-p 3000:3000部分来定义服务的端口。接下来,我们将使用
working_dir和卷定义,来传递工作目录(-w /app)和卷映射(-v "$(pwd):/app")。Docker Compose 卷的优点是我们可以是使用当前目录的相对路径。
最后,我们需要使用 environment 来传递环境变量。
定义 MySQL 服务
我们将首先定义新服务,并将其命名为 mysql,以便它自动获取网络别名。我们将继续并指定要使用的镜像。
接下来,我们将定义卷映射。
当用 docker 运行容器时,将自动创建指定的卷。但是,在使用 Compose 运行时就不会发生这种情况。
我们需要在 top-level volumes 中定义卷,然后在服务配置中指定挂载点。
只需提供卷名,就可以使用默认选项。不过还有更多的选择。
最后,我们只需要指定环境变量。
此时,我们的完整 docker-compose.yml 应该是这样的:
运行应用程序堆栈
确保没有其他的 app/db 副本首先运行
启动应用程序堆栈。我们将添加 -d 标志来运行后台的所有内容。
我们可以看到卷像网络一样被创建。
默认情况下,Docker Compose 会自动为应用程序堆栈创建一个网络(这就是为什么我们没有在 Compose 文件中定义一个网络)。
我们可以使用 docker-compose logs -f 来查看日志,-f 标志“跟随”日志,因此将在生成时给出实时输出。
服务名显示在行首(通常是彩色的),以帮助区分消息。
如果要查看特定服务的日志,可以将服务名添加到 logs 命令的末尾(例如,docker-compose logs -f app)。
此刻,你应该能够打开你的应用程序,看到它运行。
如果我们看一下 Docker Dashboard,我们会看到一个名为 app 的组。这是 docker compose 中的“项目名称”,用于将容器组合在一起。
默认情况下,项目名称只是 docker-compose.yml 所在目录的名称。
当你准备完全删除它时,只需运行 docker-compose down
默认情况下,在文件中的已命名卷不会被删除。如果要删除卷,则需要添加 --volume 标志。
安全扫描
当您已经构建了一个镜像时,最好使用 docker scan 命令对其进行扫描以发现安全漏洞。
必须登录到 dockerhub 才能扫描镜像。
运行命令 docker scan --login,然后使用 docker scan <image-name> 扫描您的镜像。例如:
扫描使用了一个不断更新的漏洞数据库,因此当发现新的漏洞时,你看到的输出会有所不同。
输出列出了漏洞的类型、要了解的 URL,以及重要的是相关库的哪个版本修复了漏洞。
还有其他一些选项,您可以在 docker 扫描文档中了解。
除了在命令行上扫描新建的镜像,你还可以配置 Docker Hub 来自动扫描所有新推出的镜像,然后你可以在 Docker Hub 和 Docker Desktop 中看到结果。
镜像分层
你知道是什么构成了一个镜像吗?
使用 docker image history 命令,您可以看到用于在镜像中创建每个分层的命令。
查看教程前面创建的入门镜像中的分层。
您将注意到有几行被截断了。如果添加 --no-trunc 标志,就会得到完整的输出
分层缓存
现在您已经看到了分层的实际应用,接下来有一个重要的经验教训可以帮助您减少容器映像的构建时间。
一旦一个层发生变化,所有下游层也必须重新创建
删除所有之前的镜像
让我们再次看看我们使用过的 Dockerfile
回到图像历史输出,我们可以看到 Dockerfile 中的每个命令都成为图像中的一个新层。
您可能还记得,当我们对镜像进行更改时,必须重新安装 yarn 依赖项。
有办法解决这个问题吗?每次构建时都围绕着相同的依赖关系发布并没有多大意义,对吧?
为了解决这个问题,我们需要重新构造 Dockerfile 来支持依赖项的缓存。
对于基于 node 的应用程序,这些依赖项在 package.json 文件中定义。
那么,如果我们首先只复制这个文件,安装依赖项,然后再将其他东西拷贝进去,怎么样?
然后,只有在 package.json 发生更改时,我们才重新创建 yarn 的依赖关系。有道理?
首先更新 Dockerfile,将其复制到
package.json中,安装依赖项,然后把其他东西都拷贝进去。
在与 Dockerfile 相同的文件夹中创建一个名为
.dockerignore的文件,其内容如下。
.文件 是一个简单的方法,选择性地复制图像相关的文件。
在这种情况下,应该在第二个 COPY 步骤中省略 node_modules 文件夹,因为否则,它可能会覆盖 RUN 步骤中命令创建的文件。
为了进一步了解为什么在 Node.js 应用程序和其他最佳实践中推荐使用这种方法,请看他们关于对 Node.js web 应用程序进行 Dockerizing 的指南。
使用 docker Build 构建一个新的镜像。
你会看到所有的图层都被重建了,非常好,因为我们对 Dockerfile 做了很大的改动。
现在,对 src/static/index.html 文件进行修改(比如将 <title> 更改为 The Awesome Todo App)。
现在使用 docker build -t getting-started . 再次构建 Docker 镜像。
这一次,您的输出应该看起来有些不同。
首先,您应该注意到构建速度要快得多!
并且,您将看到步骤1-4都具有 Using cache。
多阶段构建
虽然在本教程中我们不会深入讨论,但是 多阶段构建 是一个非常强大的工具,可以帮助您使用多个阶段来创建一个镜像。他们有几个优势:
从
运行时依赖中分离构建时依赖通过只发送你的应用程序需要运行的内容,来减小所有镜像的大小
Maven/Tomcat 示例
在构建基于 Java 的应用程序时,需要使用 JDK 将源代码编译成 Java 字节码。
然而,JDK 在生产中是不需要的。
此外,你可能会使用诸如 Maven 或 Gradle 之类的工具来帮助构建这个应用程序。
这些在我们最终的镜像中也不需要。
在本例中,我们使用一个阶段(称为构建)来使用 Maven 执行实际的 Java 构建。
在第二阶段(从 tomcat 开始),我们从构建阶段复制文件。
最终镜像只创建的是最后一个阶段(可以使用 --target 标志覆盖该阶段)。
React 示例
在构建 React 应用程序时,我们需要一个 Node 环境来编译 JS 代码(通常是 JSX)、SASS 样式表,以及更多的静态资源(HTML、JS 和 CSS)。
如果我们不进行服务器端渲染,那么我们甚至不需要生产构建所需的 Node 环境。
为什么不将静态资源迁移到静态 nginx 容器中呢?
这里,我们使用一个 node:12 镜像来执行构建(最大化分层缓存),然后将输出复制到 nginx 容器中。
容器编排
运行的容器在生产环境中是不能变动的。
您不希望登录到一台机器并简单地运行 docker run 或 docker-compose up,为什么呢?
是的,如果容器死了怎么办?你如何在多台机器之间进行扩展?
容器编排解决了这个问题。像 Kubernetes, Swarm, Nomad 和 ECS 这样的工具都以略微不同的方式帮助解决了这个问题。
一个普遍的想法是拥有一个可以接收预期状态的“管理员”。
这种状态可能是“我想运行我的 web 应用程序的两个实例并公开端口80”,然后管理员查看集群中的所有机器,并将工作委托给“工作者”节点。
管理人员观察变化(例如容器退出),然后用 实际状态 反来映 预期状态。
Last updated